你绝对没有认真考虑过的GPRs当中多路选择器和地址译码器
CPU微观之旅:追踪一条ADD指令的奇幻漂流
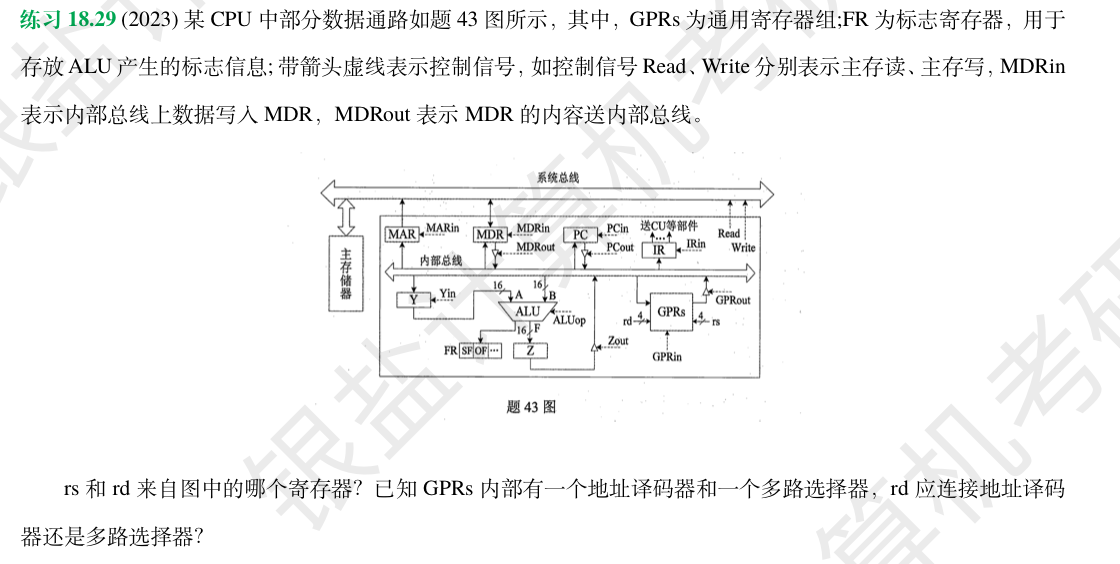
追踪一条我们习以为常的指令——add R3, R1, R2——从诞生到消亡的全过程。
这条指令的任务很简单:把寄存器R1和R2里的值加起来,然后把结果存入寄存器R3。但在看似简单的背后,是CPU内部众多部件精密、优雅的协作。我们的焦点,将放在通用寄存器组(GPRs)的两位核心“门卫”身上:负责“读”的多路选择器,和负责“写”的地址译码器。
**第一站:指令译码
当add R3, R1, R2这条指令的机器码被加载到指令寄存器(IR)后,控制单元(CU)会立刻对其进行“审问”(译码)。它会解析出以下关键信息:
-
操作码:
add,告诉算术逻辑单元(ALU)准备做加法。 -
源寄存器地址 (rs):
R1的地址(例如,在32个寄存器中,地址为00001)。 -
源寄存器地址 (rt):
R2的地址(例如,地址为00010)。 -
目标寄存器地址 (rd):
R3的地址(例如,地址为00011)。
第二站:读操作——多路选择器(MUX)的“多对一”数据汇集
任务:我们需要从32个通用寄存器中,精确地取出R1和R2的值,并将它们送到ALU。
这是一个典型的 “多对一” 场景:我们有多个数据来源(R0-R31的值),但需要将其中一或两个汇集到唯一的出口(ALU的输入总线)。这时,多路选择器(Multiplexer, MUX)闪亮登场。
一个多路选择器就像一个智能数据漏斗。它有多个数据输入,但只有一个数据输出,通过“选择信号”来决定哪个输入能通过。
MUX的结构示意图:
(来自 R0 的数据) ───┐
(来自 R1 的数据) ───┤
(来自 R2 的数据) ───┤
... ├───> [唯一的输出 (例如: 送到ALU的A端口)]
(来自 R31的数据) ───┘
↑
|
[ 5位的选择信号 (来自 IR 的 rs 字段) ]
数据流转过程:
-
分派选择信号:控制单元将指令中的
rs字段(R1的地址00001)送到第一个MUX的选择端。同时,将rt字段(R2的地址00010)送到第二个MUX的选择端(因为需要同时读取两个数)。 -
数据筛选:
-
第一个MUX接收到
00001信号后,立刻搭建起一条内部通路,使得其32个输入中只有R1的数据能够流向它的输出端口A。 -
第二个MUX接收到
00010信号后,只有R2的数据能够流向它的输出端口B。
-
-
数据就绪:现在,
R1和R2的数值已经安然无恙地出现在了ALU的两个输入端口上,静候计算。
小结:在读操作中,MUX扮演了数据筛选器的角色,根据指令给出的地址,从“多”个寄存器数据源中,精确地选出“一”个,完成了一次高效的数据汇集。
第三站:ALU执行——核心计算
这一步相对简单。ALU接收到控制单元的“加法”命令后,将端口A和端口B送来的两个数值相加,产生一个结果。这个结果会被暂时存放在ALU的输出锁存器(如图中的Z寄存器)中。
第四站:写操作——地址译码器的“一对多”控制分配
任务:现在,ALU产生了一个唯一的结果,我们需要把它精确无误地存入目标寄存器R3,同时确保其他31个寄存器不受任何影响。
这是一个典型的 “一对多” 场景:我们有一个数据来源(ALU的结果),需要将它写入多个可能的目标中的某一个。这时,地址译码器(Address Decoder)将发挥其关键作用。
地址译码器不传输数据,它只负责传递“开门”信号。它接收一个地址,然后只激活与该地址对应的唯一一根输出控制线。
地址译码器的结构示意图:
┌───> [写使能信号 for R0]
├───> [写使能信号 for R1]
├───> [写使能信号 for R2]
[ 5位的地址输入 ]──────────────┤ ...
(来自 IR 的 rd 字段) ├───> [唯一的有效信号 for R3]
│ ...
└───> [写使能信号 for R31]
数据流转过程:
-
数据准备:ALU的计算结果已经放在了通往寄存器组的内部总线上。
-
分派地址:控制单元将指令中的
rd字段(R3的地址00011)送往地址译码器的输入端。 -
精确赋能:
-
地址译码器接收到
00011信号后,其32根输出线中,只有连接到R3寄存器“写使能”(Write Enable)引脚的那一根线会变为有效状态(例如,从0变为1)。 -
其余31根连接到R0, R1, R2, R4...的输出线全部保持无效状态。
-
-
数据写入:此时,虽然ALU的结果数据对所有32个寄存器都是“可见”的,但由于只有
R3的“写大门”被译码器打开了,所以数据最终只会写入到R3中,覆盖其旧值。其他寄存器因大门紧闭,完美地保持了原样。
小结:在写操作中,译码器扮演了精确制导的角色,根据指令给出的地址,从“多”个寄存器目标中,精确地为“一”个数据源打开写入的通路。
旅程终点:总结
add R3, R1, R2的奇幻漂流到此结束。我们看到:
-
读操作,是多对一的数据汇集过程,其核心是数据筛选,完美适配**多路选择器(MUX)**的功能。
-
写操作,是一对多的控制分配过程,其核心是目标定位,完美适配地址译码器的功能。